去年底、我这边接手了一个新的工具产品“工作日志”(后改名叫周日报)的开发,经过近一年的功能迭代、现在已平稳地运行在线上。近两三个月又被 BU 老板进行了“强制性”推广,所以每到周四周五、大家集中写周报时流量就陡然上升,数据统计发现也已经成为我们“GTS工作台”流量排第二的产品模块了。与此同时、在产品功能和体验上,主管的要求和用户的诉求都越来越多,而这其中大多工作量都体现在前端上、并且有相当的难度…
因为量大且难、导致了不少非技术问题,宝宝心里苦… (缺少能真理解的人)
我个人之前一直认为日志也是“生产力”产品,就像 Mac 电脑、Office 软件等。但在上次跟同事聊到这个产品有没有可能卖出去的时候、想到了另一个词“管理工具”,瞬间就觉得这个词套在“周日报”这个产品上很贴切。周日报如果只是起到“信息同步”作用的话,它就不能算是生产力工具、反而变成是有“负向”作用的解决行政任务的管理工具。
因为这个产品的 PRD 毕竟是产品团队写的,产品的价值对错、我其实不必负主要责任。
本文主要还是介绍下技术方面的一些结果。其中“编辑页面”的截图
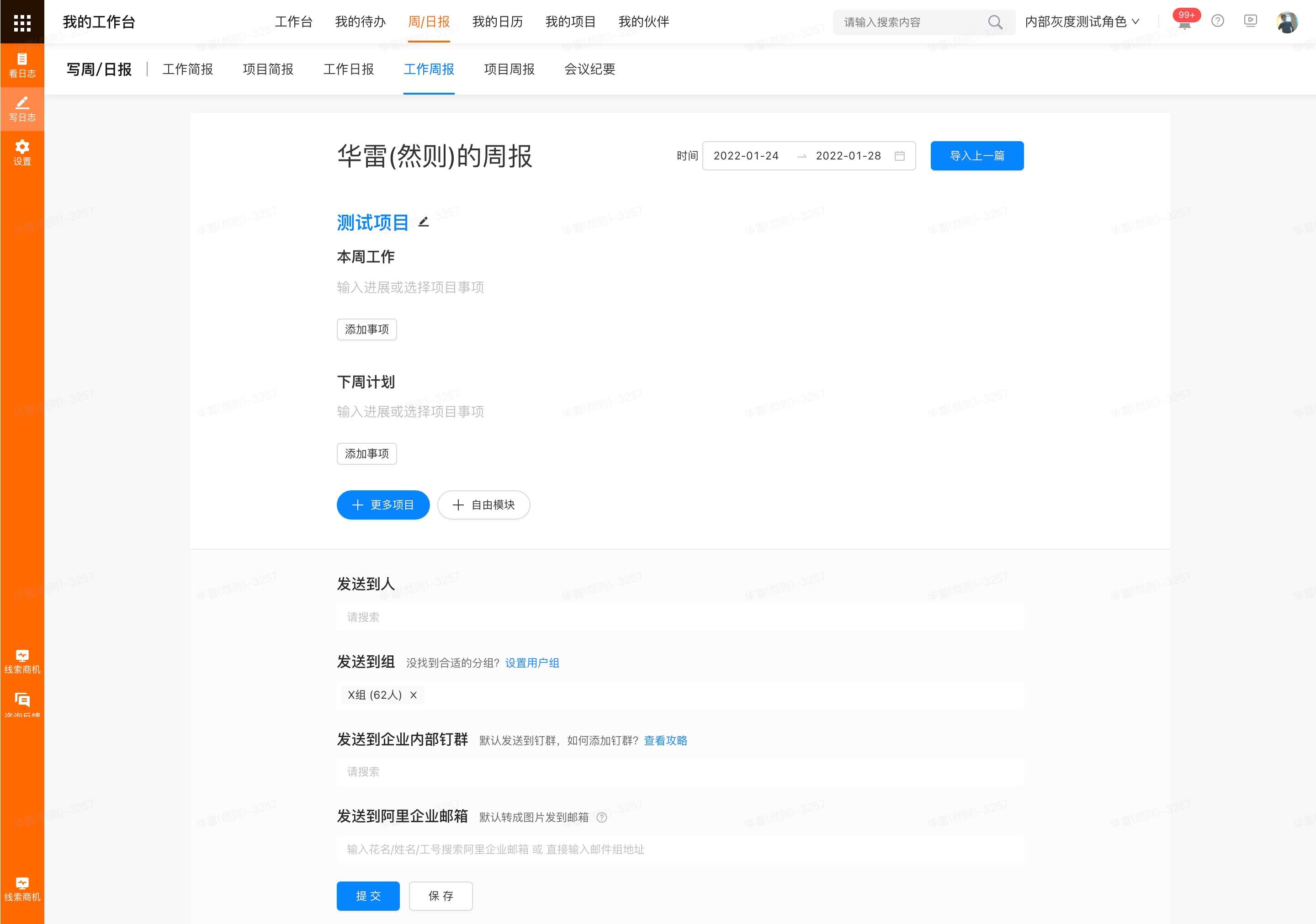{kind=link}
另附“查看页面”的截图
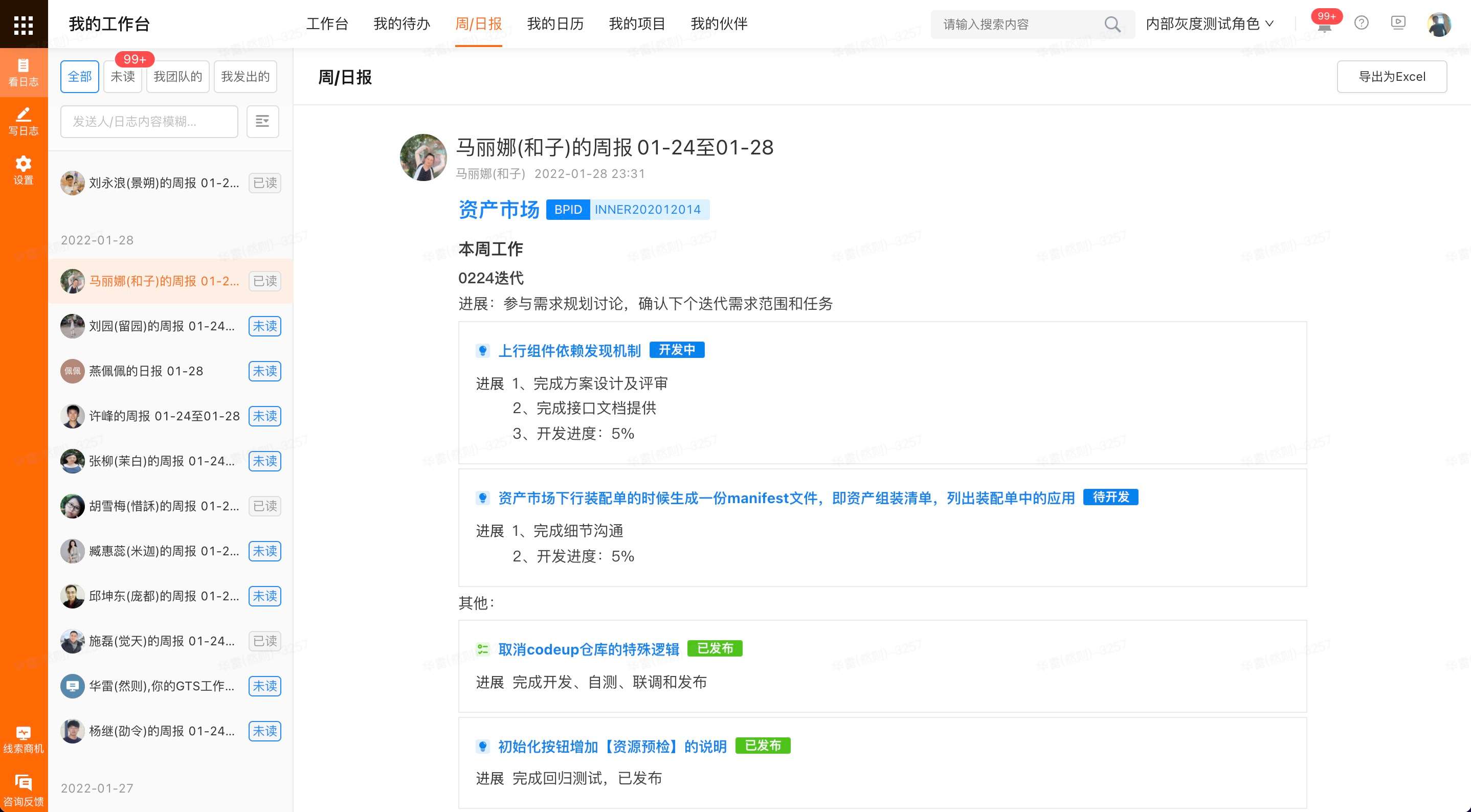{kind=link}
总体架构
如果是重度的周日报用户,写完一篇周报很可能需要花至少一小时、那么过程中“书写”体验就至关重要了。与此类似的就是我们写一篇文档的体验,所以、我认为周日报是“在线文档”的一个比较典型的场景化应用,并且拥有文档的基础必备功能(当然不像 office 或 腾讯文档 这类专业文档有更多丰富功能)。另外我们附带了业务特色,比如与GTS工作台的”人员/钉群/邮箱/消息”、协同域”项目/事项”等做了关联和打通。以下是其总体架构图:

技术细节
从架构图上乍一看东西好像不多,但其 复杂度 比一般的应用要高很多。除了设计上的复杂性之外,也遇到了很难的各类专项问题。
数据结构
因为要支持可配置的页面模板和区块,所以数据结构设计上就需要很多的嵌套和关联 这也导致了更多的工作量,数据结构设计具体如下:
- 六层(
tpls -> pages -> nodes -> sections -> tasks -> extInfo)嵌套的数据结构; - 数据关联:
tplID_pageID_sectionID标记为全局projID传给其他sections -> tasksprojId 变动后需再刷新数据; - 数据状态:“初始态、编辑态、提交态” 跨态部分同步、部分修改;
- 数据与事件:既有耦合又有分离,不能完全数据驱动。
数据结构的设计是起到核心基础架构作用的,在这之上就是各类“专项”问题。
保存问题
这个大概是“最复杂”的专项问题了,涉及到 保存的“场景、策略、内容、冲突” 各方面。我们的编辑页面 URL 主要有两个参数 templateId 和 id 其值都是唯一数,比如 https://xxx/worklog/editor?id=81e7365bffbd494caa7283cd12ab8e45&templateId=1b1db88bd08245f2b860bb8d802fdd68 而保存过程的可见变化就体现在 URL 参数里,以下做详细介绍。
一、保存的场景:
- 手动点击 保存 按钮时、或者每隔 30s 需要定时保存。
- 浏览器 tab 切换,即浏览器的 pageVisible 事件触发时。
- 页面内的模板 tab 切换、或者点击浏览器前进后退按钮时,相应 URL 里参数 templateId 和 id 变化时。
二、保存的策略:
- 页面内模板的 tab 切换时,需要先保存成功切换前的页面数据、再用后端新数据渲染页面。
- 点击切换的时候 url 里的 templateId 立即变化,这时在初始化的
useEffect和保存的Submit函数里这个值就有新旧区别。需要在旧数据保存成功后再更新数据、监听保存的结果。 - 新数据获取后、需要更新 URL 里的参数 id,此时要避免重复请求数据。
- 点击切换的时候 url 里的 templateId 立即变化,这时在初始化的
- 浏览器 tab 切换时、在 pageVisible 事件里有 visible hide (“切走/切回来”) 的区别。
- 切走保存、避免之前内容丢失。
- 切回来也会立即调用保存、这是为了判断当前页面是不是已过期 (同一页面多开场景)
- 因为页面内存在“模板切换”的 tab,而页面是这个模板下的一个实例、受到模板切换动作的影响很大,这也导致了额外的大量复杂度。
- 我们比一般在线文档保存逻辑更复杂地方之一就体现在“模板切换”这块。
三、保存的内容:
- 页面内存在 多实例 的富文本编辑器,除了分别收集正文内容、还要分别提取出 @人 的业务数据。
- 存在许多和业务相关的三方引用,比如工作台项目、事项、人员数据,时间选择器等。
四、保存的冲突:
同一个编辑页面,在PC或移动端里”多开“时、需要内容过期策略。操作场景比如:
- 在某个正在编辑的页面、浏览器 tab 右键 复制一个同样页面出来。
- 在其中一个页面(新旧区别)里、再切换 模板tab 使其 URL 改变。
这就需要有一个”锁“的策略,加锁(没有解锁)的核心逻辑是:
- 模板切换时(即URL里templateId变化),立即调用 landAndGetLock 接口。
- 在页面保存时、即调用 save 接口,把 lockVersion 传给后端。
- 以上两个接口都返回最新的 lockVersion 用来下次再 save 时传给后端;并且两个接口都会返回此页面是否“已过期/多开”的状态。
因为没有解锁的操作,一个页面“一旦过期”、就无法再把页面内容保存成功,不能自动解除过期(可以刷新页面)。
在实现锁的功能后,我们遇到了个 断网又联网 的情况下出现了页面过期的问题、这个尤其值得说一说。这个问题非常难发现、同时又非常难排查,经过多次梳理才搞清楚了情况!
断网时后端 save 接口返回失败,前端因此没收到 save 后返回的 lockVersion 值,就把下次要传给后端的 lockVersion 参数设为了 undefined 。这时如果还是断网状态、虽然每隔 30s 会再调用一次 save 但也没问题、因为到不了服务端、也不会调用成功。而如果再联网、那么调用 save 就能到达服务端,此时服务端发现参数 lockVersion 是 undefined、就把 save 后的返回值里 lockVersion 设为了 null,这时前端把本地 lockVersion 更新为后端返回的 null,等下次前端再调用时、相应就传了
lockVersion: null给后端。而后端要求 lockVersion 是必填,但实际收到了 null 就返回了 页面过期 的错误码。
上边描述还原的是当时排查问题的过程、看着还是比较绕的,总结一下就是:
- lockVersion 是后端生成的,前端只是在用户新打开页面时获取它,保存时再原样传给后端。
- 后端要求这个字段是必传的、也不能为空,但 断网又联网、破坏了这个链路。
这个事情的影响还是非常大的,因为我们的用户一般用的都是笔记本、还有很多出差或赶飞机的同事,“断网再自动联网”的情况很常见。碰到这情况用户就纳闷:我也没多开新页面、怎么周报写着写着就提示“页面过期”了…?!(页面过期会有补救措施、确保用户的内容不会丢失)。虽然发现问题原因后、很容易就解决了,但这个问题真是太难了!
保存问题-后续
解决完了这诡异的断网问题后,不禁深感这种“在线文档”的坑之大。看来对于一个更加完善的在线文档产品来说,支持前端的“离线编辑和存储”是必需的功能。但这显然又带来了更多要解决的问题、比如联网后怎么同步后端数据、差异怎么解决…
我们现在不支持离线、导致还有个现存问题:在第一次自动调用保存接口之前写的内容、如果不手动保存直接关掉页面、那就全没了。也许你会说浏览器不是有 beforeunload 事件可以监听吗?但问题来了:一是浏览器每次都会弹出“是否关闭”的模态框、体验很不好,二是即便调用保存接口、也不能阻止用户在保存成功前就关闭了页面、导致很可能没保存成功。
可见这个保存问题,在有时间有精力了、还是需要彻底解决才行!
钉钉编辑器
我们的富文本编辑器使用的是钉钉文档的底层编辑器,首先它的功能是很强大的、但由于我们产品一个页面存在多个编辑器实例,导致了一些额外成本和问题。
- 多个编辑器实例怎么共用一个工具栏?
- 无法同时选中不同编辑器的内容。
- 编辑器的“上传图片、@人”插件、需要接入业务定制接口。
- 编辑器提供的“划词评论”功能对 UI 侵入大,导致只能自己重新实现。
小节最后、再罗列下其他功能点
- 支持导入上一篇日志、发送后编辑;编辑和预览状态切换。
- 发送时支持地理位置定位、添加公司园区。
- 支持发送自定义群组、钉群、邮件,导出图片。
- 支持各维度的查看、搜索。
- 支持导出日志内容到 Excel 数据分析。
至此,我们周日报的主要技术和功能点已介绍完毕,我们回到主题之二、讨论下周日报的“父亲” – 在线文档,应该怎么做?
在线文档
如一开始就提到,个人认为周日报这个产品是在线文档的一个场景化应用,前边介绍的技术实现和问题里、抛开有业务特色的部分外,其他的在在线文档里都会有体现。但从数据结构和多富文本实例等纬度看周日报,我们最初也把它当成一个 大的复杂的表单 而不是在线文档。所以,真正的在线文档是什么样,最重要的能力有哪些,和表单的区别在哪里?
数据结构区别
- 文档型:钉钉/语雀文档,一个文档可以嵌入“卡片、附件、iframe、子文档”等几乎任何模块。
- 表单型:钉钉日志、GTS周日报,多个文档被放到类“表单”的外围数据结构里。
以上两种顶层数据结构的设计方式,实质有非常大的架构区别、由此也带来很大的技术实现差别。而真正的在线文档、应该采用前一种设计方式,这也是和表单的一个明显区别。前一种设计方式,能带来 充分 的灵活性,比如:
- 无限嵌套的层级结构。
- 能支持完全自由灵活的显示布局方式。
- 可以针对单个文字、单个图片等进行完全精细的控制。
国外的 Notion / coda 文档就支持上述功能,这也能让其瞬间变身简单无代码(低代码)平台。但也正因为有这么强大灵活的特性,导致开发成本、相比 表单型文档 也高了很多。
在线文档最重要的能力是什么
除了网页上简单输入框不需要编辑器外、其他文档产品必然需要一个编辑器,所以编辑器可能是普通文档产品最重要的功能,但其实它只是在线文档的一个最基础功能。市面上有各种各样的编辑器,理想情况下,在线文档也不应该绑定到某个编辑器上、而是可以把它当做可替换的轮子。
从这个角度看、在线文档最重要的能力应该是 “在线、协同”,落到实际、有在线就会有离线、有协同就会有冲突,所以必然也要解决“离线、冲突” 这些背后的问题。这些能力的实际功能体现就是“自动保存、离线存储、版本记录、协同编辑”等。
这也很容易联想到、我们日常使用的 Git 工具/代码IDE编辑器 等就有这方面的一些功能,我们大多数时间都是在本地做 git commit / save 等操作、离线状态下做了很多事情,只有少数时间做 git push / conflict 的协同。再推导下、在线文档的底层能力、如果不只是单单的离线存储、而能有更完善的“离线操作”支持,那就更好了。另外这些能力能否抽象出来、是否可移植到其他应用呢?我认为很有可能。
总结
近几年国外的 notion/coda 和国内的“腾讯文档/飞书/语雀/钉钉文档”等文档型产品大力发展,导致这本来属于垂直领域的产品却似乎走向了大众、并大有要替代 office 的趋势。另外这些产品都往基于浏览器的 SaaS 方向发展,导致对前端的需求非常强烈、前端在此方向从业人员也越来越多。
过去一年个人作为“独立”参与者、对此也是百感交集,最大的体会仍然是:这是一个大坑、适合有规模的专业团队干,而不适合一般的业务团队来做。一年多前开发的架构图设计工具、也是类似的情况。这么说最大的原因是“投入巨大、收益单一”、投入产出比不足。
当然也许是因为个人目前格局不够、理解狭隘了。
不管怎么样,我相信没有白走的路!感谢这个宝贵的经历。