本文是内部分享的脱敏版本,由于团队内有国外同事、前十多分钟说英语。 整体内容比较多,前一部分做了手工翻译、后边内容翻译软件自动翻译。
最近在支撑后端监控产品 Argos 的开发,其中在 E2E 的建设上投入了不少精力。基于团队内 Apmplus、Slardar 前端监控产品之前的 E2E 实践经验,结合了 Argos 复杂的业务,并且改变了和 QA 同事的协作方式,进而总结出了一些新的经验。全篇分为两大块做介绍:
- 开门见山地把“实操”过程的各种要点展示出来,如果你也在写E2E、这部分经验可以直接拿来使用。
- 简单讨论一些高级话题,比如“测试金字塔、如何写有效的测试、作用和效果”等,这部分经验可以拿来做参考。
Based on the previous E2E practical experience of Apmplus, Slardar. We combined complex Argos business, and changed the way of collaboration with QA colleagues, then summarized some new experiences. The whole article is divided into two big blocks:
- Show the various “practical key points” directly. If you are also writing E2E, the experience can be used directly.
- Briefly discuss some advanced topics, such as “test pyramid, how to write effective tests, functions and effects”, etc. This part of the experience can be used as a reference.
实操要点 | Practical key points
流水线 E2E 配置 | Pipeline E2E configuration
Argos 的线上发布流水线里已经配置了 cn/i18n/TTP 等环境的 e2e节点,原来节点跑的是“全量测试用例”、耗时过久而且机器容易出异常、经常会阻碍发布流程,做了一些优化:
- 全量的测试用例改为在 定时巡检任务 里运行,每天至少自动运行一次。
- 线上发布时只跑“白屏兜底”测试用例、只测试 cn/i18n 环境。
Argos’ online release pipeline has been configured with e2e nodes on “cn/i18n/TTP” environments. The original nodes ran “full test cases”, which took too long and the machine was easy to exception and often blocked the release process. So we made some optimizations:
- The full test cases are changed to be run in scheduled tasks, run automatically at least once a day.
- When online release, only run “blank screen” checker cases and only test cn/i18n environments.
用例case复用 | Use case reuse
在前端开发中,我们经常复用代码,比如:
- 同一个组件,在多个页面是“复用”的 (比如报警规则创建、各类图表) 。
- 同一个数据源,复用在多个页面、或相同页面的不同模块。
QA同学虽然是基于用户界面功能编写用例文档、但其文字描述也应该考虑到如上复用的场景,这样就能和实际运行的代码完全对应起来,也方便统计用例集的覆盖度。
In front-end development, we often reuse code, such as:
- The same component is “reused” on multiple pages (like alarm rule creation, various charts).
- The same data source is reused in multiple pages or different modules on the same page.
Although QA mates write use case docs based on user interface, their text descriptions should also take into account the above reuse scenarios, so that they can completely correspond to the actual running code, and it is also convenient to count the coverage of the use case.
录制 & 元素选择问题 | Recording & element selection issues
新用例的编写、可以优先使用”用例录制工具”来提高效率,但一般情况下、生成的代码仍然需要经过修改后才能正式使用。录制用例之前需要进行前置环境配置,比如设置登录信息(通过 sso 或其他方式获取登录信息)。 用例录制功能主要 帮助生成 如下示例的“选择元素” 这部分代码:
await page.element({
choices: [
page.findByRole('option', { name: '生效中' }), // highest priority
{ css: '.arco-volc3-select-option:nth-child(1)' },
{ xpath: 'id("arco-volc3-select-popup-2")/div/div/li' }
]
}).click();
pagepass 测试框架是按照 choices 数组里选择器的顺序从高到低排优先级,即如果第一个选择器能命中、就会忽略剩余其他的。实践中需要注意:
- 确保第一个选择器能起作用(可以拿第二个选择器做备用),而应该忽视或删除第三个选择器。
- 页面最好同时只存在一个 select option / modal 等弹窗。
- 只在特别有必要时才设置
data-testid属性。
如上代码示例、第三个选择器 xpath 是不可靠的,其中
arco-volc3-select-popup-2这个 id 里的 2、很可能会在每次代码构建后被改变。另外有复杂但准确的解法,利用 arco(和antd类似) 组件在各类 popup 触发元素上提供的aria-controls属性值。
数据问题 | Data issues
Argos 的几大业务模块、前端页面上的交互功能差别较大:
- 报警模块,主要是大量“表单和表格”类型的增删改查。
- 监控模块,有大量的“图表”、要验证 图表渲染 是否正常。
- 日志模块,主要功能是“数据查询”,要验证 “数据准确性、edge case、大量数据渲染性能” 等。
特别是对于监控和日志业务模块,需要探索和解决 “数据的生成方案、数据覆盖度” 的问题。
- 单点数据:对单个接口 mock 入参和出参。(也可尝试数据构造工具)
- 闭环数据:比如 报警规则的“创建-展示-编辑-删除”、日志模块数据的“上报-查询-展示-过期”,形成和业务逻辑对应的数据闭环。
深入到“数据细节”,比如很多模块都用到的 metrics 图表数据、一般由两部分构成:
- 时序数据 “时间点-值”,构成曲线。
- 重要意义的业务数据,构成图表上的 mark line area 等区域 (比如 报警次数 报警事件)。
其中 时序数据的“起止时间”需要很明确,这样才能构成一个“稳定可测试”的图形,才能通过 screenshotDiff 等功能、验证 图表渲染 是否正常。
实际演示两个用例文件:
- 报警规则的“创建-展示-编辑-删除” (代码地址 rule-edit.ts))。
- 监控图表的截图对比 (代码地址 monitor-serverOverviewChart.ts)。
更深入 | Deeper
测试金字塔 | Test Pyramid
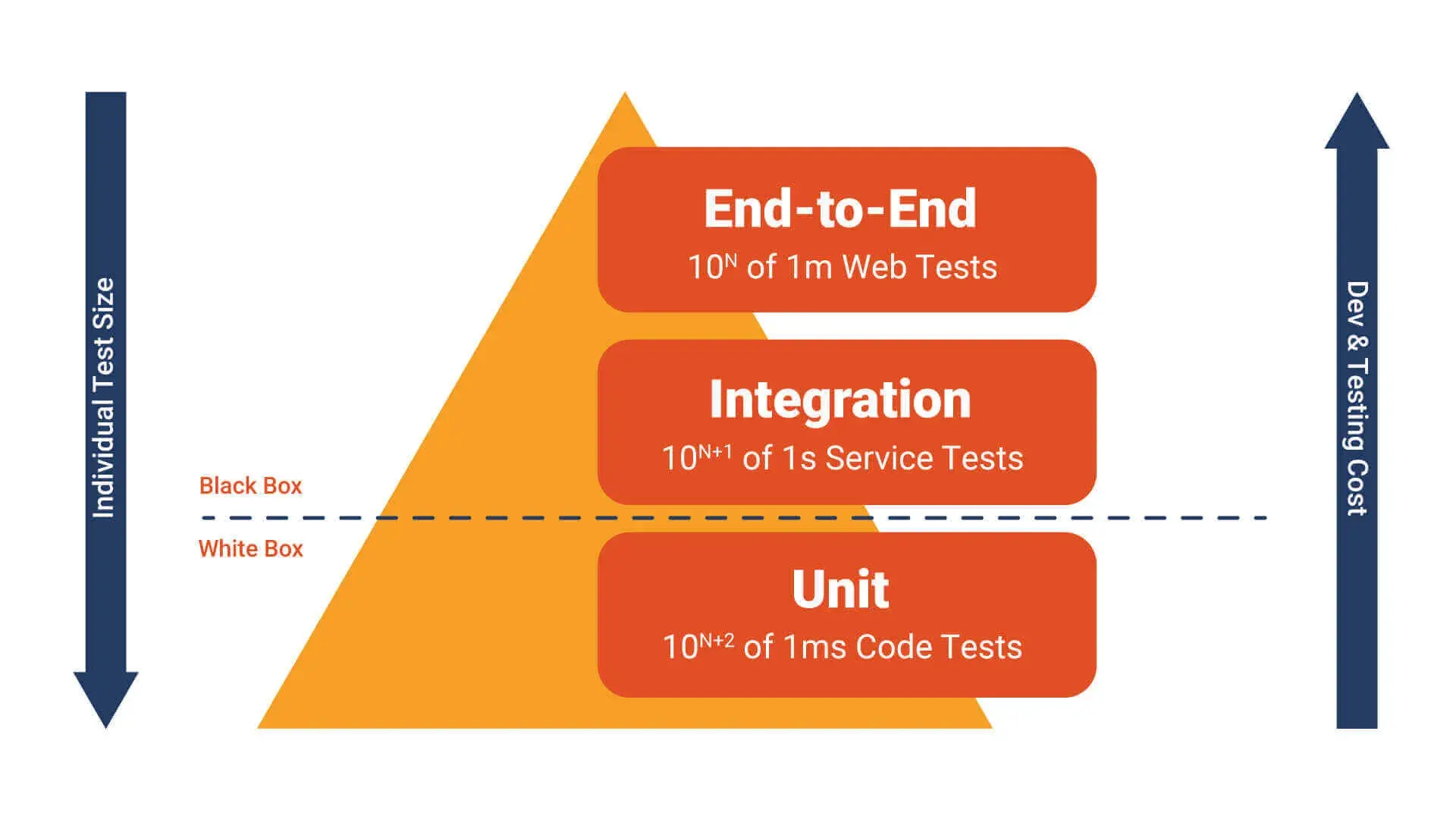
按照“测试金字塔”理论模型建议,测试类型应该是 70% 的单元测试、20% 的集成测试和 10% 的 (UI)E2E 测试。这个模型最早追溯到2009年、那时候前后端代码是融合的开发模式,而且前端代码占比很小。所以它应该是以“前后端”所有代码作为基数、来建议不同类型的测试占比,而不是前端和后端分开的。 从 前后端 代码的功能角度看:
- 后端代码有大量原子性的业务逻辑、对应着大量的“单测”,是很容易且自然的事。
- 塔中间的 集成测试 几乎也全体现在后端系统之间的功能集成上。
- 塔顶的 E2E 测试,也更多是从后端接口调用出发,因为除了前端 UI 界面、也有 OpenAPI 等其他调用。
这么看这个模型的话,其实是完全针对后端设计,只有处在塔尖的 E2E 需要涉及到 前端页面 时,才产生一点点关联。
前端测试理论 | Front-end testing theory

上图来自 testingjavascript 可能是比较适合前端代码的测试理论,它引入了“静态检查”工具、来替代一部分的单测代码,另外不同于后端、前端代码 的构成可能更加多样。
- 基础框架、三方UI组件和工具库,它们大多已包含比较完整的测试、其中“单测”部分占比可能较大。
- 业务组件,如果封装了复杂的交互、需要有部分的单测和snapshot等测试。
- 业务代码,容易变化、测试成本较高ROI较低,其中“数据获取和处理”的部分、适合用单测覆盖。
综上,因为“UI组件本身的交互功能、业务数据的处理”都已被单测等测试类型覆盖到。剩下 “UI + 数据” 的 integration 测试、其实就可以由 E2E 测试来完成。
不管是哪种类型的测试金字塔,一般都有个共识:上层是对下层的一个补充,即如果上一层发现了错误、下层没发现,应该写一个低层级测试去覆盖这个错误。
如何写有效的 E2E 测试 | How to write effective E2E tests
很容易找到怎么写有效的“单测”,比如:
- 一个测试应当只检查一件事,避免条件逻辑,不要写永不失败的测试,避免冗余测试,避免Mock不确定的依赖 等等。
- 要写“可测试的代码和设计”:避免复杂的私有方法,组合优于继承,使用new要当心 等等。
- 一味追求代码覆盖率,往往写出无效的单元测试。把测试代码当成是“一等公民”,跟业务代码一样需要CR。
写 E2E case代码时、也应该遵守上述指导原则。另外 E2E 是综合性测试,在开始写代码之前:
- 需要充分理解业务全貌,能理清业务里的重点功能脉络。
- 对于 复杂的业务逻辑,需要 全面覆盖 各类分支的场景,防止漏测。
不管是单测还是E2E、写出有效的测试,能让投入的时间回报最大化;尽量减少你在测试中投入的精力,并最大化测试提供的好处。
分工协作 | Division and cooperation
和之前团队内 E2E 实践相比,这次最大的进步之一是合作模式上。我们逐步把“写case”的工作交还给了QA同学,而前端来负责兜底解决环境运行等其他问题。经过一段时间的实践,证明出了更大的收益。
- 因为有了 QA 专业质量视角,测试 case 写的更加全面。
- 发现了更多的潜藏缺陷,能一起制定出更合理的考核指标。
当然因为 QA 同学没掌握专业的前端技术,用例代码的架构和抽象上做的不够好、但影响不大 可以被 CR 修正。
总结 | Summary
不同的测试类型有不同的责任边界,而E2E测试需要用线上真实的数据进行测试、涉及到前后端数据库各系统,是可以真正验证应用程序可行性的测试、有着更高的置信度。
另外有相关经验的同学会发现,在“写测试用例”的过程中、就能发现被测应用的许多缺陷或优化点,有时候甚至比测试运行过程中发现的问题更多更重要。
我们在编写用例时就发现了比如 “页面元素层级不对、部分数据未在页面上展示出来” 等比较明显的问题。也发现了复杂的问题:比如页面展示的内容是由“多个串行或并行请求“返回的结果决定,但他们到达时间不同、展示出来不同的结果,这不符合预期。
我们现在提倡“测试左移、监控左移”等各种概念,都是为了达到“问题左移”的目的,最终不让问题出现在用户面前。